논문 링크: [1512.00567] Rethinking the Inception Architecture for Computer Vision
Rethinking the Inception Architecture for Computer Vision
Convolutional networks are at the core of most state-of-the-art computer vision solutions for a wide variety of tasks. Since 2014 very deep convolutional networks started to become mainstream, yielding substantial gains in various benchmarks. Although incr
arxiv.org
한 줄 정리
- 컨볼루션 분해(Factorization):
- 큰 컨볼루션(예: 7×7)을 작은 컨볼루션(3×3 또는 비대칭 1×n + n×1)으로 분해하여 계산 비용 절감
- 차원 축소(Dimension Reduction):
- 수용 영역(receptive field)의 공간 크기를 줄이면서도 정보 손실을 최소화하도록 설계
- 정규화 기법:
- Batch Normalization: 보조 분류기(auxiliary classifiers)에도 적용하여 학습 안정성 향상
- Label Smoothing: 모델이 특정 라벨에 과도하게 확신하지 않도록 정규화하여 일반화 성능 향상
- 효율적인 성능:
- 계산 비용을 최소화하면서도 높은 분류 정확도를 달성.
Abstract
2014년 이후 주류가 된 컨볼루션 네트워크는 다양한 성과를 거두기 시작했다. 모델의 크기, 계산 비용이 증가하면서 대부분의 task에서 즉각적으로 성능 향상이 이루어졌지만 계산 효율성과 효율적인 파라미터 수는 여전히 주요하게 다뤄졌다.
본 연구에서는 적절하게 분해된 컨볼루션과 정규화를 통해 추가 계산을 가능한 효율적으로 활용할 수 있는 네트워크 확장 방식을 탐구한다.
성과는 다음과 같다.
- 단일 모델 사용: ILSVRC 2012 classification challenge에서 21.2%의 top-1, 5.6%의 top-5 error 달성
- 4가지 모델의 앙상블: ILSVRC 2012 classification challenge에서 17.3%의 top-1, 3.5%의 top-5 error 달성
1. Introduction
2012년 ImageNet 대회에서 AlexNet이 우승한 이후 2014년부터 더 깊고 폭넓은 네트워크를 활용해 네트워크 구조가 크게 향상되었고 VGGNet과 GoogLeNet은 ILSVRC 분류 대회에서 높은 성능을 보였다. GoogLeNet은 Inception V1이다.
VGGNet은 단순한 구조와 높은 성능이 장점이지만 높은 계산 비용이 단점이었다. 때문에 그 후에 나온 GoogLeNet은 Inception 아키텍처를 사용해 당시 제한된 자원 하에서도 뛰어난 성능을 발휘하도록 설계되었다.
- 파라미터 수 비교
| 모델 | AlexNet | VGGNet | GoogLeNet |
| 파라미터 수 | 6천만 개 | 1억 8천만 개 | 5백만 개 |
본 논문에서는 컨볼루션 네트워크를 효율적으로 확장하는 데에 집중하며 Inception 아키텍처가 구조적으로 유연하고 병렬로 처리된다는 점을 강조한다.
2. General Design Principles
아래 4가지 원칙을 지키면 성능을 높이고 파라미터수를 줄일 수 있따.
1. Avoid representational bottlenecks, especially early in the network
네트워크 초기 단계에서 representational bottlenecks을 피해야 한다.
💡Bottleneck (병목 현상): 네트워크의 특정 지점에서 정보가 지나치게 압축되어 다음 단계로 전달될 중요한 정보가 손실될 수 있는 상황
Feed-forward 네트워크는 정보가 입력층에서 시작해 출력층 (classifier or regressor)으로 한 방향으로만 흐르는 신경망이다. 이 구조에서는 입력 데이터가 한 번만 처리되고 이후 결과가 출력층으로 전달되는 과정으로 이루어진다. 논문에서는 이를 비순환 그래프(acyclic graph)라고 표현한다. 여튼! 네트워크에 부분 부분마다 정보가 얼만큼 전달되는지 알 수 잇는데 이때 극단적으로 정보를 압축하는 bottleneck을 피해야 한다는 것이다. 특히 네트워크 초기 단계에서 이런 bottleneck이 발생하면 나머지 네트워크가 손실된 정보를 복구할 기회가 없기 때문에 모델의 성능이 저하된다. 일반적으로 출력의 크기는 점진적으로 감소하는 것이 올바른 방향이다.
하지만 또 정보를 압축할 때 representation의 크기가 작다고 해서 반드시 정보량이 작은 것이 아니다. 왜냐하면 중복된 정보를 제거하면 차원을 작게 줄이면서도 정보량을 유지할 수 있기 때문이다.
즉, 모델이 입력 데이터를 더 잘 이해하고 학습할 수 있도록 돕기 위해 초기 레이어에서 정보가 지나치게 압축되는 bottleneck이 발생하지 않도록 설계해야 한다. 또한 네트워크는 정보를 점진적으로 축솨며 데이터의 중요한 특징을 유지하도록 만들어야 한다.
2. Higher dimensional representations are easier to pro cess locally within a network.
고차원 representation은 지역적으로 처리하기 더 쉽다.
고차원의 representation은 데이터의 특징이 더 많은 차원으로 확장된 것으로 고차원 공간에서는 특징이 서로 잘 분리된다. 예를 들어 고양이 이미지에서 눈, 코, 입과 같은 세부적인 특징들이 독립적으로 표현된다는 것이다. 이렇게 분리된 피처들은 네트워크가 데이터의 중요한 패턴을 더 쉽게 학습할 수 있도록 돕는다. 때문에 데이터의 특징이 고차원 공간에서 분리되어 있으면 네트워크는 각 특징에 대해 더 적은 연산으로 효과적으로 학습할 수 있다.
지역적으로 처리하기 쉽다는 이야기는 다음과 같다. 컨볼루션 네트워크는 입력 데이터를 타일 (작은 패치) 단위로 처리하는데 고차원 representation을 활용하면 각 타일에 대한 정보를 더 세밀하게 분리해 처리할 수 있다는 것이다. 예를 즐어 이미지의 작은 영역에서 고양이의 눈을 분석할 때 고차원의 representation은 논의 곡선, 색 등 다양한 정보를 독립적으로 분석할 수 있게 된다.
3. Spatial aggregation can be done over lower dimen sional embeddings without much or any loss in rep resentational power.
Spatial aggregation (공간적 집계)는 낮은 차원에서 수행할 수 있다.
💡 Spatial aggregation (공간적 집계): 데이터의 여러 위치 (공간적 정보)를 합치는 작업, 즉 컨볼루션 연산을 통해 인접 픽셀의 정보를 결합하는 것
컨볼루션 연산을 수행하기 전에 입력 데이터의 차원을 줄여도 성능에 큰 문제가 없다는 것이다. 차원 축소는 입력 데이터의 특징을 적은 수의 필터나 축으로 압축하는 것인데 예를 들어 256차원의 데이터가 있으면 이를 64차원으로 줄이고 나서 3 x 3 컨볼루션을 수행해도 정보 손실이 적게 발생한다는 것이다.
그 이유는 다음과 같다. 인접하는 픽셀 간의 값들은 보통 강하게 상관되어 있어 데이터의 중요한 정보를 유지하면서 불필요한 세부 정보를 제거할 수 있게 된다.
결국 고해상도의 이미지를 처리할 때 필터 수를 줄여 차원 축소를 한 다음 Spatial aggregation (공간적 집계), 즉 컨볼루션 연산을 적용하면 차원 축소 덕분에 연산량이 절반으로 줄지만 중요한 특징을 유지시킬 수 있게 되는 것이다. 계산 효율성이 높아지고 학습 속도가 증가하며 중요한 정보도 유지가 된다.
4. Balance the width and depth of the network.
네트워크의 폭과 깊이를 균형 있게 맞추는 것이 좋다.
여기에서 말하는 네트워크의 폭과 깊이는 다음과 같다.
- 폭 (width): 한 layer에 포함된 필터의 개수 또는 뉴런의 수 → 폭을 늘리면 하나의 layer에서 더 많은 feature를 동시에 학습할 수 있음
- 깊이 (depth): 네트워크의 layer 개수 → 깊이를 늘리면 데이터를 더 복잡하게 처리하고 더 추상적인 패턴을 학습할 수 있음
네트워크의 각 단계에서 필터 수 (폭)와 네트워크의 깊이 간의 균형을 맞추면 최적의 성능을 얻을 수 있다. 또한 폭과 깊이를 동시에 늘리면 더 높은 품질의 네트워크를 얻을 수 있으며 주어진 계산 자원 내에서 균형있게 분배하는 것이 중요하다.
깊이만 늘린다면 Gradient vanishing 문제가 발생해 학습 속도가 느려지거나 제대로 학습이 진행되지 않을 수 있고, 폭만 늘린다면 계산량이 급격히 증가해 모델이 불필요하게 복잡해질 수 있다.
3. Factorizing Convolutions with Large Filter Size
GoogLeNet은 컨볼루션을 계산적으로 효율적인 방식으로 Factorizing한 사례로 초기 성능 향상의 많은 부분이 차원 축소를 매우 적극적으로 사용된 데에서 비롯되었다.
예를 들어 1×1 컨볼루션 레이어 뒤에 3×3 컨볼루션 레이어를 사용하는 경우를 생각해볼 수 있는데 위에서 말한 것처럼 인접한 활성화값들의 출력은 높은 상관관계를 가지게 된다. 따라서 집계하기 전, 활성화를 줄이면 유사하게 표현력 있는 Local representation을 유지할 수 있게 된다.
💡 1 x 1 컨볼루션 레이어 뒤에 3 x 3 컨볼루션 레이어를 사용하는 이유
컨볼루션 레이어는 입력 데이터에서 특징 (feature)을 추출하는 필터를 적용하는 연산으로 필터의 크기는 한 번에 처리할 데이터의 공간적 범위를 결정한다고 생각하면 된다.
- 1x1 컨볼루션: 한 픽셀(또는 작은 단위)의 정보를 처리하며 채널별로 연산을 수행
- 3x3 컨볼루션: 3×3 크기의 작은 영역을 처리하며 공간적 정보(주변 픽셀 간의 관계)를 캡처
자세하게 설명하자면 1x1 컨볼루션은 입력 데이터의 차원을 축소하거나 특징 공간에서 채널 간 상호작용을 수행한다. 여기서 3x3 컨볼루션과 다른 점은 공간적 정보를 다루지 않는다는 것이다. 예를 들어 입력 데이터의 채널 수가 256개라면 1×1 컨볼루션으로 이를 64채널로 줄일 수 있다. 그렇다고 데이터의 중요한 정보를 요약하지 않는 것이 아니다. 1×1 컨볼루션은 단순히 채널 수를 줄이는 것이 아니라 데이터의 중요한 정보를 요약하고 뽑아낸다. 3x3 컨볼루션은 공간적 정보를 추출하는 흔히 우리가 이해하는 컨볼루션 연산이다.
1x1 컨볼루션 연산 후 3x3 컨볼루션 연산을 수행하면 1×1 컨볼루션으로 채널 수를 줄여 계산량을 줄이고 이후 3×3 컨볼루션으로 공간적 패턴을 학습하게 되는 것이다. 이렇게 하면 채널 수가 줄어들어 계산 효율성이 향상되며 파라미터가 감소하고 학습 속도가 향상된다.
이해가 안 간다면 아래 사이트에서 직접 그려주신 그림을 보면서 이해하면 이해가 쉽다.
해당 논문에서는 다양한 설정에서 컨볼루션을 Factorizing하는 다른 방법들을 탐구하는데 특히 계산 효율성을 높이는 데에 집중한다. Inception 네트워크는 Fully convolutional 구조이기 때문에 각 가중치가 활성화당 한 번의 곱셈 연산에 해당한다. 따라서 계산 비용의 감소는 파라미터 수의 감소로 이어지며 이는 적절한 Factorizing을 통해 더 분리된 파라미터를 얻을 수 있고 결과적으로 학습 속도를 빠르게 만들 수 있다는 것을 의미한다. 또한 단일 컴퓨터에서 학습이 가능하게 했다고 한다.
3.1. Factorization into smaller convolutions
그렇다면 왜 한 번에 큰 필터를 써서 특징을 추출하지 않는걸까?
큰 공간 필터 (ex. 5x5, 7x7)를 사용하는 컨볼루션은 계산량 측면에서 매우 비효율적이라고 한다. 예를 들어, 컨볼루션은 동일한 필터 개수로 이루어진 컨볼루션에 비해 배 더 많은 계산이 필요하게 된다. 물론 5x5 필터는 큰 공간에서 정보를 뽑아내기 때문에 넓은 영역을 한 번에 봐 멀리 떨어져있는 데이터 간의 관계를 더 잘 학습할 수 있다는 장점이 있다. 하지만 이렇게 동일한 효과를 내면서 파라미터를 줄여 계산 효율성을 높이는 방법을 탐구해야 한다고 해당 논문에서는 이야기한다. 필터 크기가 클수록( ex. 5×5) 더 넓은 범위의 데이터를 한 번에 처리할 수 있지만 계산량이 급격히 증가하기 때문이다.

위 맨 마지막 큰 네모를 5x5 필터로 컨볼루션한다고 했을 때 거의 Fully connected 네트워크처럼 작동한다. (한 번에 25개의 입력 픽셀의 정보를 처리) 이를 위 그림처럼 3x3 필터 2개로 대체하면 계산량을 줄이면서도 비슷한 표현력을 유지할 수 있게 된다. 해당 논문에서는 변환불변성(Translation Invariance)을 사용했다고 하는데 변환불변성이란 데이터의 위치나 형태가 약간 바뀌더라도 네트워크가 동일한 결과를 낼 수 있는 능력을 의미한다고 한다. 예를 들어 고양이 사진에서 고양이가 이미지의 왼쪽에 있든 오른쪽에 있든 여전히 고양이는 고양이로 인식해야 한다는 것이다. 즉, 여기에서 필터가 위치에 상관없이 패턴을 인식할 수 있으므로 두 개의 3×3 필터로도 5×5 필터와 비슷한 결과를 낼 수 있다는 말이다.
얼마나 계산량이 줄어드는지 살펴봤을 때 계산량이 로 감소하여 약 28%의 상대적 이득을 얻을 수 있다.

그렇다면 이러한 대체 방식이 표현력 손실을 초래하는지, 컨볼루션 레이어에서 입력 데이터를 그대로 전달해 계산의 복잡성을 줄이는 것이 목표라면 왜 첫 번째 레이어에서 선형 활성화를 사용하지 않는지 실험을 통해 살펴볼 필요가 있다.
실험 결과, 표현력의 손실은 없었으며, 첫 번째 레이어에서 선형 활성화를 사용한 경우 ReLU를 사용한 경우보다 항상 성능이 낮았다.결국 선형 활성화는 데이터를 단순히 할 뿐 비선형성을 제공하지 못 해 계산의 복잡성이 줄어듦과 동시에 복잡한 특성들을 학습하지 못한다는 것이다. 또한 ReLU로 비선형성을 추가하고 Batch Normalization(배치 정규화)을 통해 활성화를 정규화했을 때 네트워크가 더 강한 성능을 보였다.

3.2. Spatial Factorization into Asymmetric Convolutions
다음은 비대칭 컨볼루션을 통한 공간적 분해이다. 우리는 항상 대칭적인 필터 (ex. 3x3, 5x5)만 사용했지만 비대칭적인 작은 필터 (ex. 3x1, 1x3)로 분해해 계산 효율성을 높이는 방법도 설명한다.


기존에는 3x3 필터를 가장 많이 사용했다. 하지만 더 작은 필터를 사용할 수도 있는데 이때 비대칭 필터를 사용해보는 것이다. 비대칭 필터는 필터의 가로, 세로 크기가 다른 필터로 3×3 필터를 3×1 컨볼루션 + 1×3 컨볼루션으로 분해할 수 있다. 첫 번째 3×1 컨볼루션은 가로 방향에서 정보를 처리, 두 번째 1×3 컨볼루션은 세로 방향에서 정보를 처리하게 되는 것이다.
비대칭 필터의 장점은 계산 효율성이다. 3×3 필터를 3×1 + 1×3으로 분해하면 계산량을 약 33% 절약할 수 있다. 3x3 필터를 사용하면 3x3 = 9개의 연산이 필요하지만, 3×1 + 1×3 필터 계산량은 3+3=6개의 연산으로 계산량이 줄어들고 동일한 receptive field를 커버할 수 있게 된다.
또한 대칭필터보다 작은 대칭 필터와 비교했을 때 계산 효율성이 높다. 3×3 필터를 2×2 필터 두 개로 분해하면 계산량은 약 11%만 절약되는 것을 알 수 있다. (2x2 + 2x2 = 8)
모든 레이어에 적합한지 실험해보았을 때 초기 레이어(입력 이미지가 큰 경우)에서는 비대칭 분해가 잘 작동하지 않았지만 중간 크기 그리드(feature map의 크기가 12×12 ~ 20×20인 경우)에서 매우 효과적이라고 한다. 특히 중간 크기의 그리드에서 7x7 필터를 1x7 + 7x1 로 분해하면 계산량을 크게 줄이면서 표현력을 유지할 수 있다고 이야기한다.
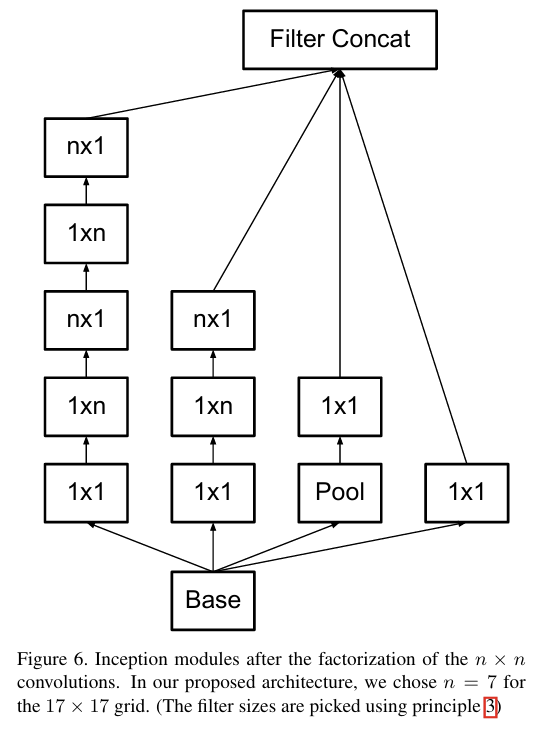

4.Utility of Auxiliary Classifiers

보조 분류기(auxiliary classifiers)가 딥러닝 네트워크에서 학습에 어떤 영향을 미치는지 살펴보는 부분이다.

보조 분류기(auxiliary classifiers)는 네트워크 중간 레이어에 추가된 작은 분류 모델로 네트워크의 최종 출력과 독립적으로 중간 레이어에서도 분류 작업을 수행하도록 설계되며 GoogLeNet에서는 2개의 보조 분류기가 사용되었다. 결과적으로 말하자면 GoogLeNet에서 Auxiliary Classifier를 활용하면 신경망이 수렴하는데 도움을 준다고 했지만 성능 향상에 크게 효과는 없었다고 한다.
사용하는 목적은 다음과 같다.
① Gradient vanishing 문제 해결: 네트워크가 깊어지면 초기 레이어로 전달되는 기울기가 약해져 학습이 잘 이루어지지 않는데 보조 분류기는 초기 레이어로 유용한 기울기를 전달해 학습을 돕는다.
② 수렴 속도 개선: 학습 초기에 네트워크가 더 빠르게 수렴하도록 설계되었다.
실험 결과, 학습 초기에는 보조 분류기가 네트워크 성능 향상에 크게 기여하지 않는 것으로 나타났지만 학습 후반부엔 보조 분류기를 포함한 네트워크가 약간 더 높은 정확도를 달성하며 더 높은 성능의 정점(plateau)에 도달했다. 이를 통해 보조 분류기는 초기 레이어의 학습을 돕는 것이 아니라 정규화 효과(regularization)를 통해 네트워크 성능을 향상시키는 것으로 보았다. 결과적으로는 성능 향상보다 정규화 효과가 있는 것으로 추측했다.
💡 갑자기 정규화 효과(regularization)?
보조 분류기에서 Batch Normalization 또는 Dropout을 사용하면, 주 네트워크의 주 분류기 (main classifier) 성능이 더 좋아졌기 때문이라고 한다.
5. Efficient Grid Size Reduction
해당 논문에서는 피처맵의 크기를 줄이는 효율적인 방법을 제안한다.
기존에는 Max pooling이나 Average pooling과 같은 풀링 연산을 사용해 피처맵의 크기를 줄이는데 이때 Representational bottleneck 현상을 방지하기 위해 필터 수 (활성화 차원)를 늘린다. 예를 들어 d x d 크기를 가진 k개의 피처맵은 풀링 레이어를 거쳐 (d/2) x (d/2) 크기의 2k개의 피처맵이 된다는 것이다. 연산량은 2(dk)^2에서 2(dk/2)^2 가 되기 때문에 연산량이 감소하지만 representation 또한 감소한다. (정보가 손실된다는 말이다.)

위 그림의 왼쪽이 위와 같은 방법이다. 풀링을 수행해 공간적 크기를 줄이고 그 후 필터 수를 늘려 표현력을 확장한다. 이 방법의 문제점은 풀링을 먼저 수행한 후 필터 수를 늘리기 때문에 공간적 정보가 손실될 가능성이 크다. 즉, Representational bottleneck 문제가 발생할 수 있다는 것이다.
반면 위 그림의 오른쪽 방법은 먼저 필터 수를 늘린 후 풀링을 진행하는 방식이다. 이 방법을 수행하면 표현력이 확장되고 정보 손실이 방지되지만 그만큼 계산 비용이 증가한다.
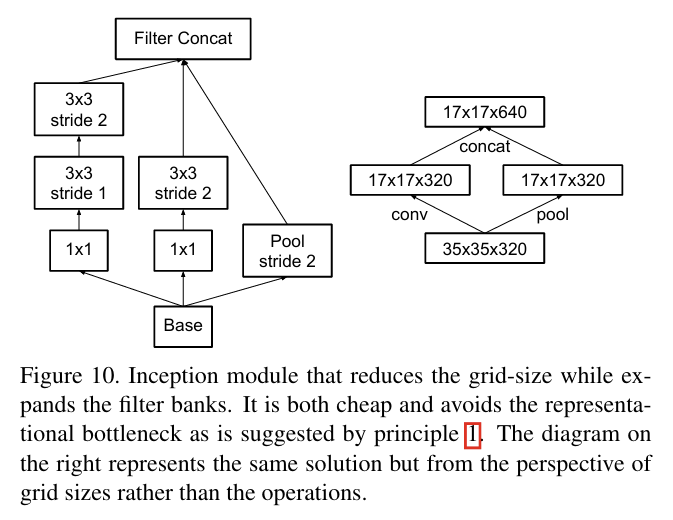
때문에 해당 논문에서는 병렬로 stride-2 block을 사용하는 방식을 제안한다.
즉, stride가 2인 풀링 레이어와 컨볼루션 레이어를 병렬로 사용해 두 블록의 출력을 병합(concatenate)하여 병목 현상 없이 계산량을 줄인다.
6. Inception-v2


앞에 소개한 내용들을 적용해서 만든 것이 Inception-v2이며 주요한 특징은 다음과 같다.
- 7x7 컨볼루션을 3개의 3x3 컨볼루션으로 Factorizing했다.



- 위 그림 5번에서 보이는 바와 같이 35x35 레이어는 Inception 모듈 3개로 구성되며 각 모듈은 288개의 필터를 포함하고 있다고 한다. 또한 이후 위에서 소개한 병렬로 stride-2 block을 사용하는 방식을 사용해 17x17 크기의 피처맵으로 축소된다.
- 위 그림 6번에서 보이는 바와 같이 17x17 레이어는 Inception 모듈 5개로 구성되며 이후 또 피처맵을 축소시킨다.
- 위 그림 7번에서 보이는 바와 같이 8x8 레이어는 가장 작은 그리드 크기이며 Inception 모듈 2개로 구성된다.
네트워크는 총 42개의 레이어로 구성되었으며 GoogLeNet(22-layer)에 비해 계산 비용이 약 25%정도만 더 비싸고 VGGNet 보다 훨씬 효율적이다.
7. Model Regularization via Label Smoothing
해당 논문에서는 Label Smoothing이라는 정규화 기법을 제안해 모델의 Overfitting을 방지하고 더 잘 일반화할 수 있도록 돕는 방법 또한 제안한다.
기존의 교차 엔트로피 손실은 분류 task에서 많이 사용되는 손실함수로 이때 모델은 실제 라벨의 확률을 최대화하고 나머지 라벨의 확률을 최소화하도록 학습한다.

이러한 방법은 문제점이 존재한다.
① 과적합: 모델이 모든 학습 데이터에서 실제 라벨의 확률을 100%로 예측하게 되면 새로운 데이터에 일반화하지 못할 수 있다.즉, 모델이 각 학습 데이터 x를 실제 특정 정답에 대해 확률을 100%로 예측하도록 학습한다면학습 데이터에는 완벽히 맞을 수 있지만 테스트 데이터에는 잘못된 예측을 할 가능성이 높다.
② 모델의 과도한 확신: 모델이 특정 라벨에 지나치게 높은 확률을 할당하면 일반화 능력이 떨어진다. 이는 모델이 예측한 확률 p(k)가 실제 정답 q(k)과 매우 가까워지면 기울기 p(k) - q(k)가 0이 되어 작아지고 학습이 느려져 새로운 데이터에 대한 적응력을 잃게 되기 때문이다.


때문에 Label Smoothing이라는 정규화 기법을 제안하는데 Label Smoothing은 라벨 q(k)를 완전히 1 또는 0으로 설정하지 않고 부드러운 확률 분포로 변환한다.
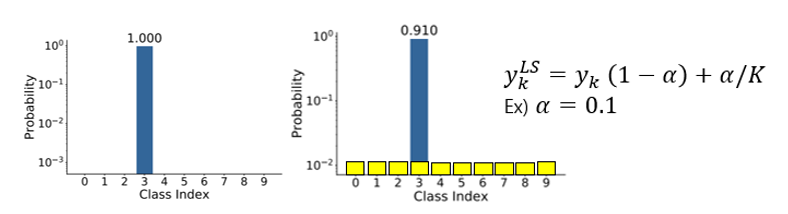
위와 같은 문제들의 발생 원인은 모델의 confidence가 높아서라고 유추할 수 있기 때문에 모델의 confidence가 낮아지도록 유도하는 간단한 메커니즘을 제안하는 것이다.
실제 정답 라벨을 y라고 한다면 라벨 분포 q(k|x) = δ_{k,y}를 위와 같은 라벨 분포로 바꿀 수 있다.
- 기존 라벨 분포: q(k|x) = δ_{k,y} → 원핫 인코딩된 라벨이기 때문에 y = k 인 경우1, 아닌 경우 0으로 채워짐
- 바뀐 라벨 분포: q'(k|x) → y = k인 경우엔 1 - ϵ , 아닌 경우 ϵ
즉, y = k인 경우 확률을 1에서 약간 줄리고 나머지 클래스에도 작은 확률 ϵ/K를 분배해 라벨 확률이 극단적이지 않게 한다. 라벨 스무딩은 간단하고 효과적인 정규화 기법으로 과적합을 방지하고 모델이 지나친 확신을 갖지 않도록 해 일반화 성능을 향상시킨다. 때문에 LSR(Label Smoothing Regularization)이라고 한다. 주요 목표를 정리하다면 다음과 같다. - Logit 간의 차이가 지나치게 커지지 않도록 함: 즉, 모델이 특정 라벨에 확률 1(=100%)을 할당하지 않도록 유도한다. - 확률 분포의 극단적인 형태를 완화: 각 클래스 확률이 극단적으로 분리되는 현상을 방지한다.
8. Training Methodology
모델 학습에 사용된 구체적인 방법과 설정은 다음과 같다.
- 배치 사이즈: 32
- 학습 에폭: 100
- 초기 실험에서는 Momentum Optimizer 사용 (momentum decay = 0.9) 했으며 최상의 결과는 RMSProp Optimizer를 사용했을 때라고 함
- 학습률: 기본을 0.045로 하고 2 에폭마다 0.94배로 지수적 감소 수행
- 학습의 안정성을 높이기 위해 Gradient Clipping (threshold = 20) 사용
- 시간에 따라 계산된 파라미터 러닝 평균을 사용해 모델 평가 수행
9. Performance on Lower Resolution Input

저해상도 Input에서의 성능을 따져봤을 때 학습 시간은 더 오래 걸리지만 최종 성능은 고해상도 네트워크와 거의 유사했다고 한다.
💡 저해상도 Input을 넣었을 때의 성능은 왜 따졌을까?
저해상도 입력은 작은 객체를 포함한 이미지 패치 분석과 같은 특정 상황에서 사용된다. 작은 객체는 보통 낮은 해상도로 표현되기 때문에 모호한 특징을 학습해 디테일을 유추하는 것이 필요하다. 이는 계산적으로 비용이 많이 드는데 따라서 동일한 계산 자원을 유지하면서 고해상도 Input과 저해상도 Input 간 성능 차이를 측정하곤 한다.
10. Experimental Results and Comparisons

위 표 3을 보면 라벨 스무딩 기법을 적용했을 때 모델의 일반화 성능이 향상된 것과 7x7 필터를 3x3 필터로 분해했을 때 계산 비용이 감소하고 성능이 유지된 것, 보조 분류기에 Batch Normalization을 적용해 성능을 향상시킨 것을 볼 수 있다.
최종 모델은 Inception-v3이며 이는 표 3의 마지막 행에 해당한다. 즉, 이전 변경 사항들을 모두 누적시켜 적용한 최종 버전을 이야기하며 ILSVRC-2012 검증 세트에서 우수한 성능을 달성했다.

11. Conclusions
Inception-v3는 높은 성능, 낮은 계산 비용, 정규화 기법의 조화를 통해 딥러닝 네트워크 설계의 새 표준을 제시했다. 특히 적은 계산량으로도 이전 최고 성능을 뛰어넘었고 저해상도 Input에서의 성능도 높은 품질의 결과를 달성해 작은 객체를 탐지하는 task에 활용 가능성을 보였다.